


Organizational Dichotomy in Streaming Teams
The reason why I quit more than one job.

I created this newsletter to cover mostly technical topics, but you should occasionally expect to see posts on topics like tech leadership, project management and team collaboration (of course, in the context of data streaming). With time I’ve realized that building and scaling teams is way harder than building and scaling software.
I wanted to share today’s topic for a while. During my career, I quit more than one job primarily for one specific reason - Organizational Dichotomy in Streaming Teams.
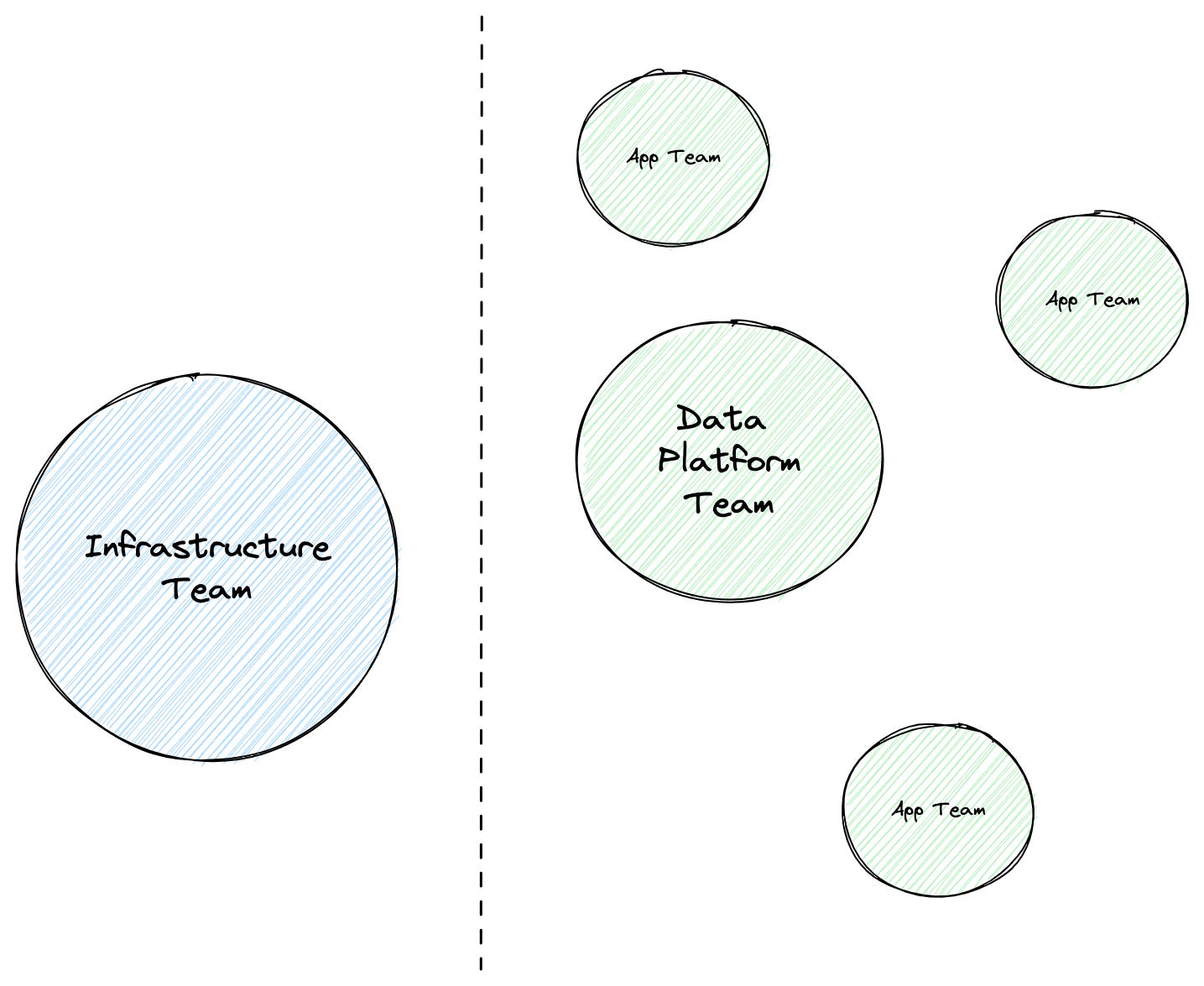
Data Infrastructure Teams
Apache Kafka has been around for a while. A lot of companies started using it around the 0.10.x release, which happened in 2016, more than seven years (!) ago. Stream processing wasn’t actively used back then - Spark Streaming was around for a couple of years, Storm 1.0 and Flink 1.0 were just released, as well as Kafka Streams. So Kafka was primarily used for the ingestion of clickstream data, as well as events and telemetry. There were also zero ways to run Kafka in some kind of managed way in the cloud: Confluent Cloud, AWS MSK, and other similar products did not exist. So, naturally, infrastructure (or platform) teams were tasked with the responsibility of running and maintaining Kafka.
I was a member of a team like that, and I interacted with a lot of similar teams from many organizations in the past. Typically, these teams were composed of people with SRE or system administrator backgrounds, and the most important metrics a team like that would care about were uptime and cost. Caring about uptime when you’re a team supporting a critical infrastructure component makes a lot of sense, but caring about cost can lead to weird incentives.
Don’t get me wrong, there is nothing bad with healthy optimizations that lead to lower costs. For instance, you can find better hardware or enforce things like compaction and binary formats. I remember simply changing batching configuration on the Kafka producer side led to a 50% reduction in Kafka brokers’ CPU utilization (which meant we could keep using the same infrastructure for higher load).
But the main driver of cost increase for any infrastructure team is more users and use cases. And most of the infrastructure teams were historically pretty bad at cost attribution (things may be improving now, but slowly).
So when a team approaches a Kafka infrastructure team with a new exciting use case that will double the overall system throughput, the typical reaction is “hell no!” followed by a more polite “let’s understand your use case better”. Increased throughput and cost could be the main concerns, but these new teams could also ask for things like automated topic provisioning and rescaling, elastic capacity, better observability or some cluster tuning, e.g. in order to enable transactions.
You might have guessed by now - these teams want to use stream processing.
Stream Processing Teams
These are a diverse bunch. In some organizations, they’re part of the Data or Data Platform department. In others, they could be application development teams who want to leverage data streaming technologies (this has become extremely popular in the last few years). Or both.
In any case, these teams usually want to innovate. E.g. power a user-facing feature with a data pipeline. Or support real-time ML inference. There are many use cases data streaming unlocks, but in the end, these teams need to talk to the Kafka infrastructure teams.
And this is when the conflict of interest happens. Kafka infrastructure teams want to minimize the changes to the systems they maintain (to ensure high uptime) and keep the system load at a stable level (to avoid rapid cost increase). Even when a cost attribution system is put in place, it doesn’t fully solve this problem - it’s still used as mostly reporting and negotiating tool, and internal teams don’t actually pay each other for services provided.
This conflict of interest can lead to all kinds of nasty outcomes a healthy organization should avoid:
Infrastructure teams can introduce additional bureaucracy to make it harder for the end users to justify big changes or load increase.
Teams could start competing directly with each other. For example, application teams could start spinning up their own infrastructure in order to stop relying on the infrastructure team services. Things could get openly hostile!
Managers play politics and try to convince the leadership that their approach is better.
I’ve seen all of it myself. It can be very painful for both sides - each side truly believes that they are doing the right thing for the business.
In the end, a reorg may happen. It’s rarely well executed, so it leads to many frustrated people, and some of them could decide to leave. Interestingly, in my personal experience, infrastructure teams always happened to be a winner. Does it mean they were right? Not necessarily, but they were better at convincing the leadership.
Is There a Better Way to Collaborate?
I don’t have a universal answer, but I’ve come up with a few strategies over the years.
For infrastructure teams:
Treat stream processing teams as partners, not users.
Understand that you can leverage high-impact stream-processing projects for your own needs, for example, to get a bigger budget.
Don’t try to have 100% uptime (unless your software literally saves human lives). Instead, introduce SLAs and error budgets. Find room to innovate.
Start using rate limiting and throttling, configure ACLs, etc. Ensure you can easily identify each user (for example, by enforcing standard client identifiers).
Scaling is not just about creating more clusters in more regions. You can also slice and dice your clusters by functions. This is a slide from my 2018 presentation about building data pipelines for Call of Duty games at Activision/Demonware:
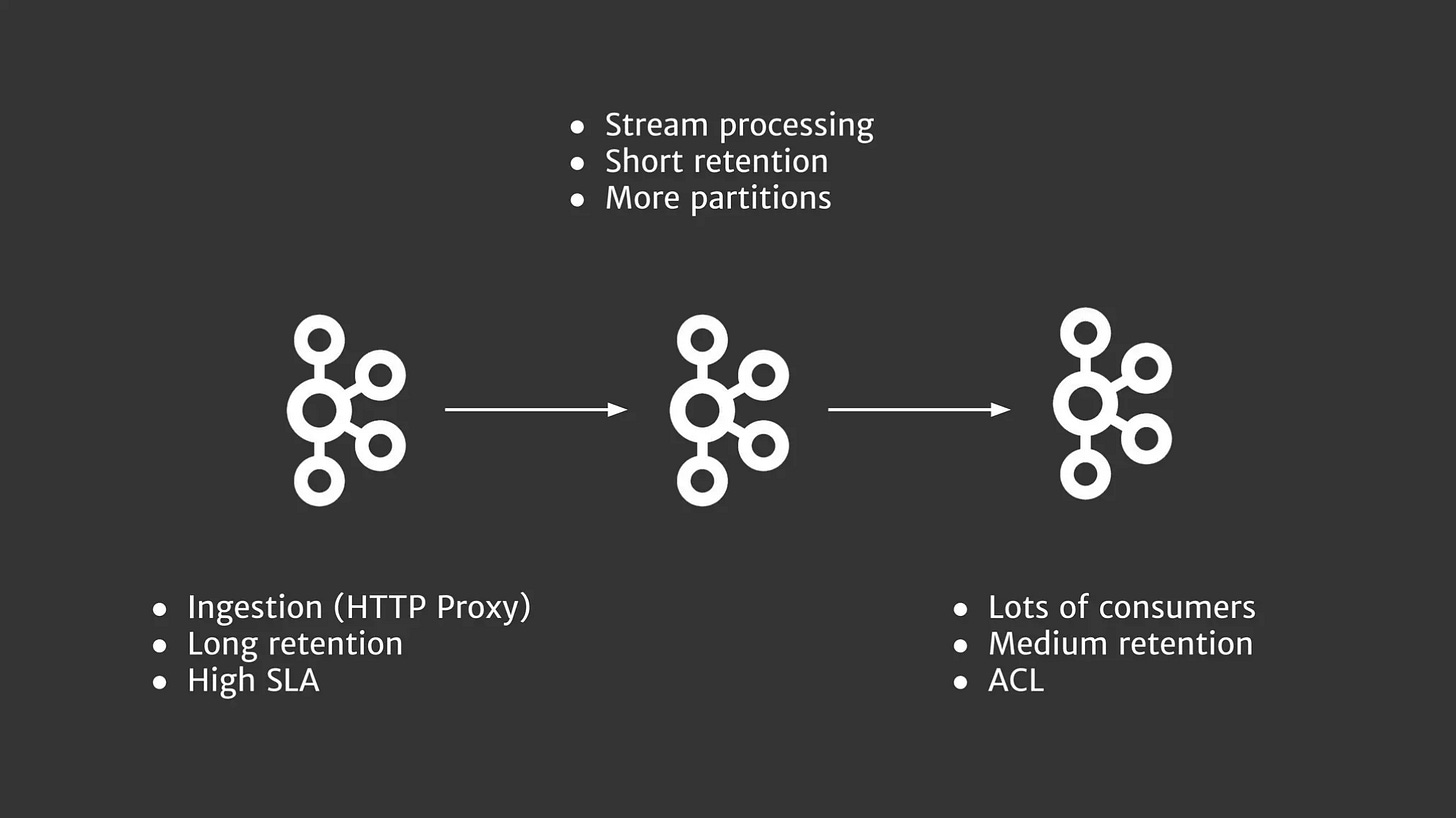
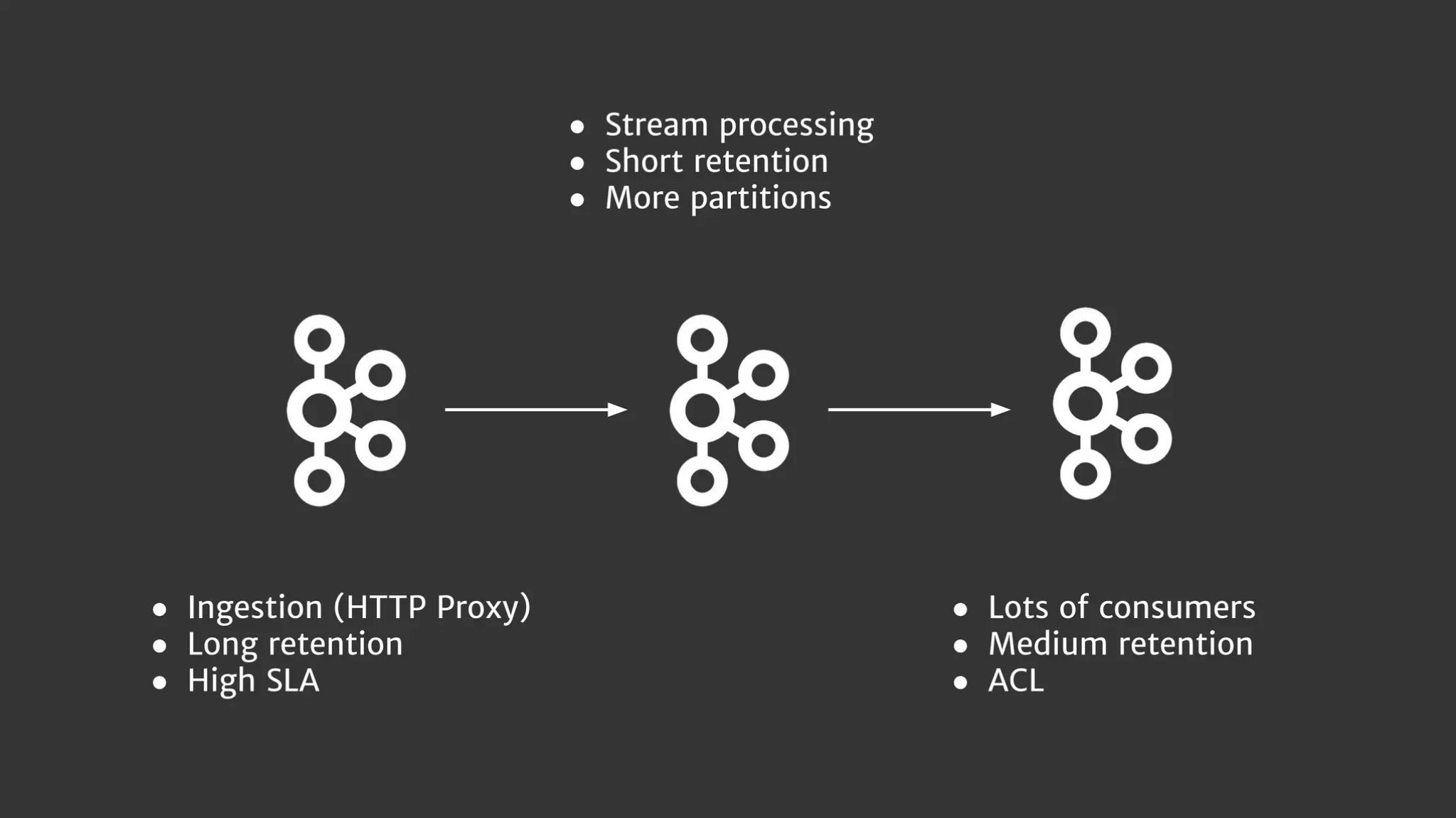
This approach made it possible to support different types of clusters for different use cases.
For stream-processing teams:
Understand that a streaming platform like Kafka is typically a shared piece of infrastructure. Carefully plan and test all the big changes you want to make. These things take time.
Ask for better observability and cost attribution. Instrument your clients with lots of telemetry.
Explain how your work contributes to the overall business goals. Brag about high-impact projects and deliverables, and make sure to acknowledge the infrastructure team when a project is shipped.
Sometimes, a simple configuration change can make a huge impact on the performance of the underlying infrastructure. Learn about the best practices and optimize things accordingly.
Reorganization
We dread this word, but sometimes a reorg may still be necessary. As a person who survived a few of them, I have the following recommendations:
Ensure that these teams end up in the same department, with the same Director. Depending on the size of the organization, sometimes you even want to have a common manager a level below, e.g. a Senior Manager.
Also, you don’t always need to merge the teams! But this primarily depends on their size.
Consult your leads! Not only tech leads but sometimes even managers might not be as involved in making these decisions… But in my opinion, it’s one of the most important decisions an organization makes, so you should always want to hear the opinions of your key employees.
Explore the Data Mesh principles. I find myself recommending these more lately, but it’s because they can actually work! Make your platform truly self-serve and ensure that the application teams have many diverse embedded experts you can trust - you don’t always need to keep things centralized.
Another option, which is more radical, is leveraging a fully managed offering from a 3rd party - e.g. Conflent, Redpanda, Aiven, your cloud vendor, etc. This could mean eliminating the infrastructure team completely. A big decision for sure, but sometimes it makes a lot of sense. Just because you’ve invested a few years into building out infrastructure doesn’t mean you should not consider one of the self-managed offerings. Getting auto-scaling and self-healing to work flawlessly is extremely challenging. You’d be surprised to hear how much toil and late-night pages your infrastructure team experienced. But they can focus on other things because running data streaming infrastructure is rarely a core business competency.
I’m pretty confident this problem is not specific to the data streaming space (but somehow, it can be more evident). A conflict between Infrastructure / Platform teams and Product teams is something that is covered more and more nowadays. Pete Hodgson wrote a great piece on How platform teams get stuff done. As usual, the human aspect of software development is the hardest one to do right.
So true, I've seen the same patterns in a few companies I've worked for too! One more consequence of separate goals for Infra vs App teams - with not enough "playground" and "load testing" environments with Kafka and/or other data intensive frameworks (like Flink) - App teams do not test every change on a "true" infra, and as a result merges and deploys from multiple features/teams cause endless failures in the one-and-only real env, sometimes taking weeks (!!) to finally get a build and deploy working, and then you start seeing weird issues in Prod when the real load is hitting your systems!