


Fluss: First Impression
Table is a new stream.

Please pledge your support if you find this newsletter useful. I’m not planning to introduce paid-only posts anytime soon, but I’d appreciate some support from the readers. Thank you!
Intro
Fluss is a new streaming platform from Alibaba that was open-sourced last week. Check the announcement post.
It’s quite similar to other streaming platforms like Apache Kafka, Apache Pulsar, Redpanda, etc., but also very different in some aspects (and has some truly unique features). It’s designed to be tightly integrated with LakeHouses like Apache Iceberg and Apache Paimon.
Currently, Fluss doesn’t implement Kafka protocol, but it’s on the roadmap. It makes it difficult to evaluate properly - right now, you have to use Apache Flink and/or Apache Paimon to interact with it. However, it’s modelled similarly: tables instead of topics, buckets instead of partitions, etc.
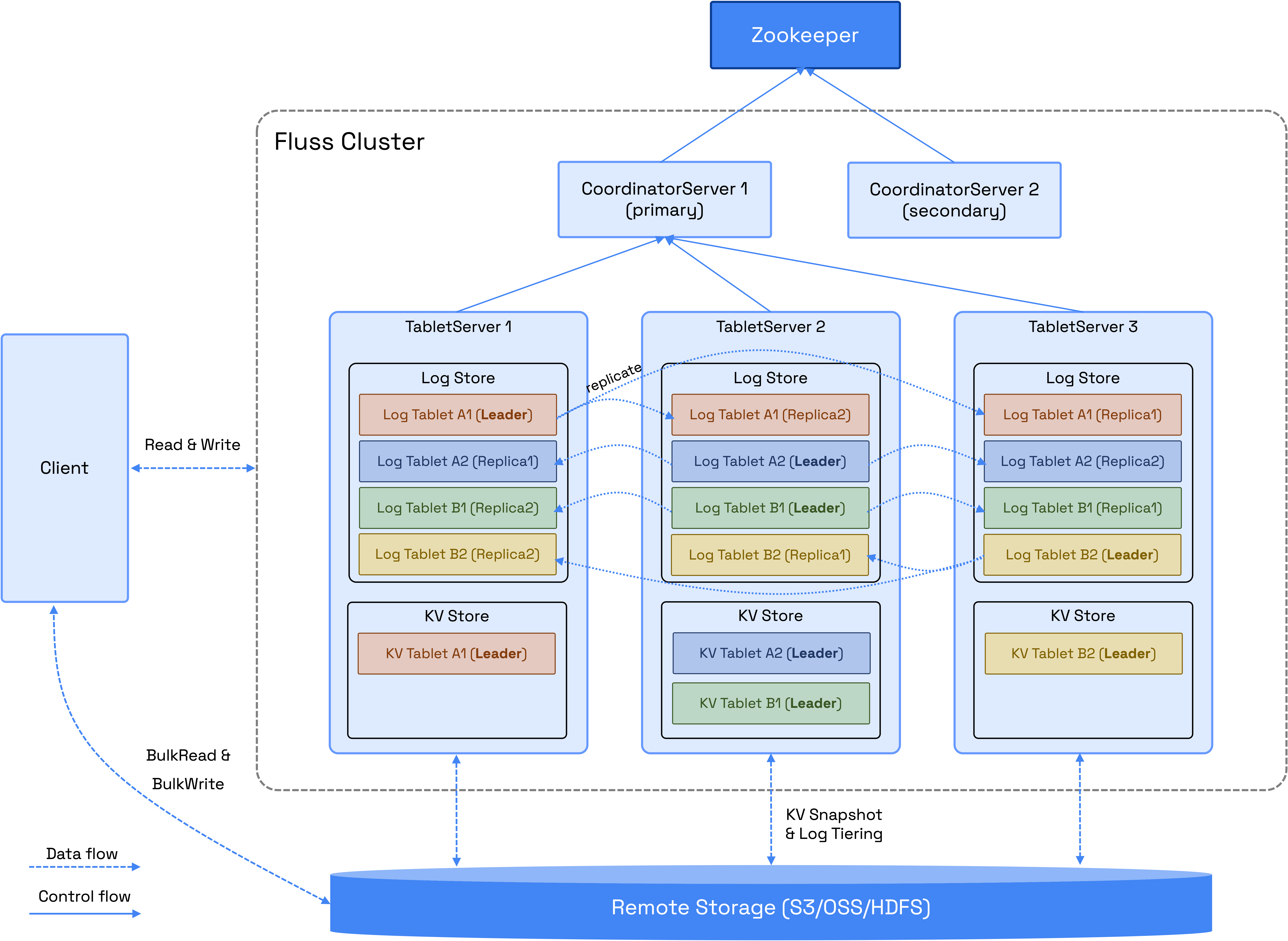
Table as a primary concept
Something that jumps out immediately when you check the documentation is that Fluss organizes data streams as schematized tables, not topics. It’s quite common to use Avro or Protobuf with a schema registry when using Kafka. However, it’s never required: to Kafka, every record value is just an array of bytes, which makes it possible to deal with semistructured or unstructured data.
Fluss demands a schema to be defined before you can write anything. I think it’ll make it much harder to use for semistructured data or data streams with schemas that need to evolve a lot.
Putting tables at the front also indicates that Fluss tries to be more of a database than a streaming platform. It makes a lot of sense given the advertised use cases: fast ingestion for real-time data and union read with LakeHouses (more on this below) for real-time analytics.
PrimaryKey Table
Fluss supports regular append-only Log Tables, as well as PrimaryKey Tables. PrimaryKey Tables seem to be the most impressive feature of Fluss at first glance. Lookup queries are Kafka’s bane: it’s very common to have a need to find a very specific subset of messages in a topic, and the only way to do it in almost any Kafka-compatible platform is to scan the whole topic from the beginning… which can take hours. Tiered storage can improve this, but not significantly.
PrimaryKey Tables are backed by RocksDB to support updates, deletes and efficient lookup queries! So, it’s possible to execute something like “SELECT * FROM users_table WHERE user_id = 123” in Flink SQL and get the results back reasonably fast.
These tables also support changelog semantics and partial updates.
There is no free lunch, and I think that the performance of these tables will be an order of magnitude lower compared to Log Tables.
More unification
I wrote this post last year:

I predicted to see data platform unification, where a streaming log (e.g. Kafka), a LakeHouse (e.g. Iceberg) and an OLAP database (e.g. ClickHouse) become much more unified “consolidated data engine” that’s easier to use and manage, not three separate systems. I stand corrected, we may see this much earlier 🙂. Several vendors have announced plans to integrate Kafka with Iceberg API (Redpanda already has Iceberg support in beta), which also applies to Fluss. It tightly integrates with LakeHouses and highlights the union read use case (also known as Hybrid Source in Apache Flink).
However, one can argue that Fluss goes beyond just these two dimensions with the PrimaryKey Table abstraction. The underlying RocksDB database can be used to serve not just efficient lookup queries but aggregations as well! There is a small example in the docs. RocksDB was also used by the Rockset database as an underlying storage for their analytical storage engine, so it’s clearly possible to pull off, at least at a certain scale.
Delta Join
This is something that I really wanted to see in Flink several years ago. It may finally happen!
The idea here is very simple:
A typical “windowless” stream-stream join needs to accumulate state for both sides forever. This becomes very challenging at scale. I wrote about this before.
Streaming platform provides a form of tiered storage with effectively infinite retention.
So, instead of accumulating data in state, we can perform a lookup when needed and query the tiered storage instead. Some form of batching will likely be required.
In a typical tiered storage implementation that’s available in Apache Kafka, Confluent or Redpanda, these lookups are not as efficient. But in Fluss, PrimaryKey Tables make it possible. I imagine Fluss contributors can also decide to add additional secondary indexes to make lookups faster.
Feel free to check the official proposal for the Delta Join in Flink.
Implementation
Fluss is implemented in Java and currently requires Zookeeper for coordination. Tables are partitioned and replicated similarly to Kafka topics. Data is stored on local disks. Overall, this feels like a reliable but somewhat dated design (what is this, 2019? where is Rust?! 😜). The roadmap already mentions planned changes like Zookeeper removal and zero disk architecture though.
When reading through some parts of the source code, I couldn’t get rid of the impression that I was looking at an amalgamation of Flink (Fluss borrowed its type system), Paimon (some design decisions) and Kafka (same abstractions, configuration, etc.). This is not surprising at all, given the team who’s working on Fluss (Flink and Paimon contributors).
Using Arrow as a primary data exchange protocol is what makes Fluss very interesting. Producers accumulate batches of Arrow vectors and send them to the server using Arrow IPC.
I invite you to check ArrowLogWriteBatch.java and MemoryLogRecordsArrowBuilder.java to understand how Arrow batches are written.
If you still question whether vectorized columnar format is a good choice for a streaming system, I recommend you to read this blog post from Arroyo. Some highlights:

Fluss protocol is implemented using Protobuf, and it’s quite easy to grasp: check the full spec here. It’s less than 1K LOC at the moment (I’m curious what it’ll look like after adding support for consumer groups…).
Conclusion
Fluss is a truly unique system that tries to model real-time data streams as schematized tables. It’s still very early, but I’d keep an eye on it: PrimaryKey Tables and Delta Joins can become killer features.
And Apache Flink users should be really excited about the roadmap:

Things like predicate pushdown and cost-based optimizer can really make a 10x - 100x difference.
Events
I’ll be speaking at these events next week:
Redpanda Streamfest. Come join us to hear my predictions about the future of data streaming!
Apache Flink 2.0: What’s to come and the impact on stream processing webinar from DeltaStream.