


Attempting to Understand Internal Consistency
I'll get there eventually.

I’ve tried to write this post several times. Each time, I realized that I didn’t have enough understanding of the underlying principles and spent more time researching. Finally, I decided to publish my understanding and learnings so far - I hope they can be useful even without answering all the questions.
I probably made some mistakes (hopefully minor ones) and a few generalizations, so I welcome any feedback!
If you’ve been working with streaming systems for a while, you’ve probably read Jamie Brandon’s Internal consistency in streaming systems post. If not, I encourage you to do it right now.
In this post, Jamie states that:
A system is internally consistent if every output is the correct output for some subset of the inputs provided so far.
He compares different technologies: Differential Dataflow, Materialize, Apache Flink, and ksqlDB.
I’m not going to re-tell the post. Just check it out, it’s worth it!
Instead, I want to share my interpretation of internal consistency and its implementation details, hopefully with very simple and pragmatic language.
I’ve never really understood the post and how Differential Dataflow maintains internal consistency until recently, when I spent several days going through the source code (and things are still somewhat vague). I also want to share what it means in the context of Apache Flink. Finally, I made some new discoveries when running experiments with Apache Flink 1.18.
About the Problem
Jamie describes the problem of calculating a balance of transactions presented as credits and debits. The most important rule to maintain in this problem:
Since money is only being moved around, never created or destroyed, the sum of all the balances should always be 0.
In the post, Differential Dataflow and Materialize always maintain consistent results (e.g. no incomplete-will-retract-this-later stuff), and the total balance is always 0. Flink and ksqlDB fail spectacularly, which means they’re not internally consistent.
And here’s the important bit: both credits and debits are based on the same transactions dataset. So, in practice, the problem can be formulated as a self-join. Keep that in mind.
Since Materialize is based on Differential Dataflow, I will mostly focus on the latter (just like the post did). But first, what is Differential Dataflow?
Timely Dataflow
Differential Dataflow is based on Timely Dataflow, so let’s cover it first.
Timely Dataflow is a low-latency cyclic dataflow computational model written in Rust. It’s based on the Naiad paper and has some documentation available. I highly encourage you to at least check the Readme. There is quite a bit of academic language, especially if you go through the source code. In the end, this is how I understand it at the moment:
It’s a dataflow system.
At its core, there is a scheduler that assigns an internal version to every input record. It can keep track of those versions when they flow through the defined dataflow graph.
Because of that, it can support very advanced computations like iterations, which allow the dataflow graph to contain cycles. This may sound like a very minor detail, but as far as I understand, it allows Materialize to build powerful features like WITH MUTUALLY RECURSIVE.
Also, these versions allow the alignment of the results of the computations in case of distributed operations like shuffles.
Let me expand the last item a bit. Any data processing framework that supports stateful operations like joins and aggregations needs to implement a form of a shuffle. A shuffle is needed to move records with the same key to the same node:
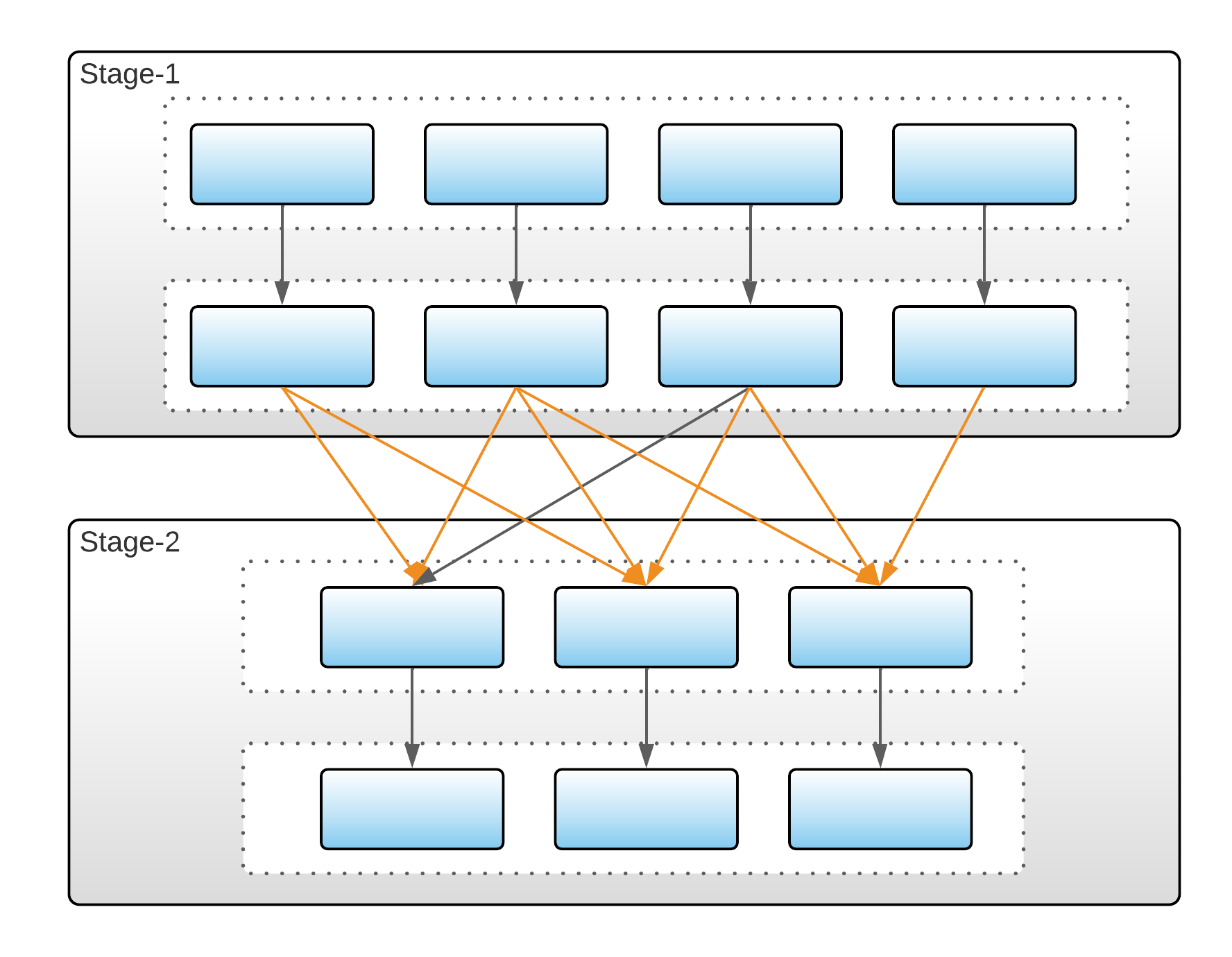
In any batch system, since the input is finite, the results of the shuffle are consistent and deterministic. However, in a streaming system, since the input is infinite, the system needs to make a decision when to emit an intermediate result. And this is where things can be widely different.
Timely Dataflow can delay intermediate results by accumulating them in buffers until all results for a certain version are received. This is one of the important features that supports internal consistency.
Differential Dataflow
Differential Dataflow (DD) is a framework for incremental computations over potentially unbounded datasets. There is a Rust implementation with some documentation and a paper.
There is also a great post from Materialize that explains how to build Differential Dataflow from scratch in Python.
Here are my main realizations:
It’s an Incremental View Maintenance (IVM) system.
It’s designed to efficiently process updates. It can reuse intermediate results and avoid recomputing from scratch. In practice, it means it’s capable of reducing a changelog of values to a single value.
From one point of view, you could say that it’s just an optimization. Getting one record instead of ten is efficient, but functionally, you’re getting the same answer in the end, right?
But from a different point, this feature also contributes to internal consistency: without it, a system could emit many incomplete intermediate results, which violates the internal consistency principle.
Current DD implementation is built on top of Timely Dataflow, but it doesn’t need to be.
You can use Timely Dataflow without Differential Dataflow just fine (in fact, this is what Bytewax does).
Internal Consistency
So, to summarize, Differential Dataflow (and Materialize) supports internal consistency because:
It can buffer intermediate results and only emit data once it observes that all records with a certain internal version have been received.
It can reuse intermediate results and “compact” changelogs.
And the self-join example described in Jamie’s post is actually trivial to support because Timely Dataflow understands that both credits and debits records are derived from transactions thanks to those internal versions.
But the more commonly used left join or inner join would be much harder to support. Imagine a typical data enrichment use case where you want to join one dataset with another. If those are represented by two separate Kafka topics, for example, as far as I understand, the user would need to implement the logic to synchronize them in Timely Dataflow. Materialize still doesn’t seem to support this functionality out of the box.
UPDATE: of course, Materialize supports all kinds of joins, but what I meant here is primarily about timestamp semantics. Materilize effectively synchronizes unrelated datasets using ingestion time. Which is great for maintaining consistency, but sometimes, your requirements dictate the use of event time.
But What About Latency?
Delaying and buffering intermediate results sounds like something that can cause latency to spike. Naiad’s paper doesn’t seem to consider it a huge problem; it describes several optimization techniques. In the end, maintaining low latency is a key Timely Dataflow characteristic.
However, in practice, it seems rational that the latency and correctness would be competing with each other, and sometimes waiting for accurate results a bit longer will be required.
Flink’s Perspective
As Jamie showed, Flink doesn’t support internal consistency. But why?
I’ve updated Jamie’s example to Flink 1.18, here’s a branch. One thing you immediately learn after checking the Flink UI: Flink’s planner is not smart enough to reuse transactions as a single source:
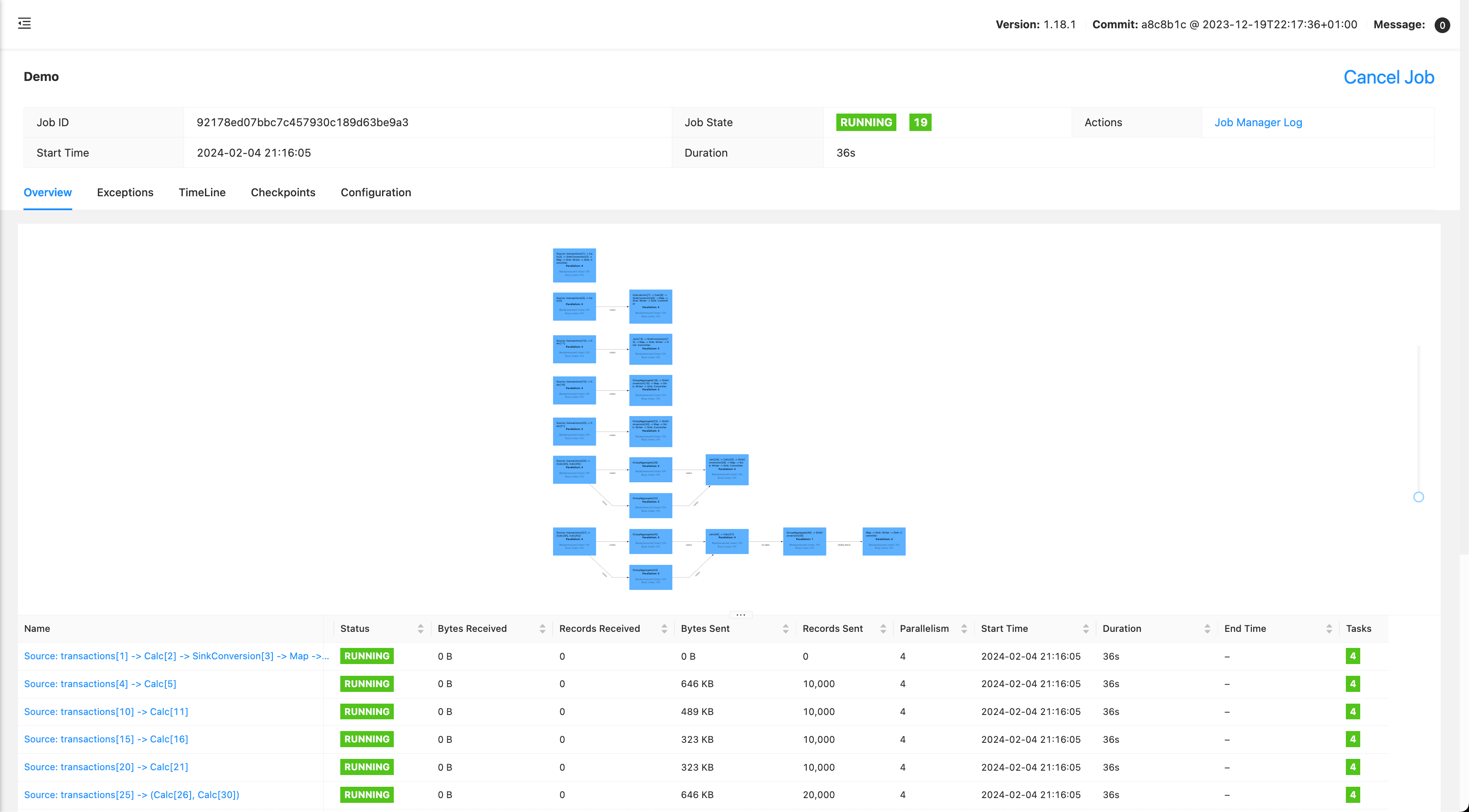
Since it duplicates transactions source for each transformation, you can forget about any kind of data synchronization right away: these are treated by Flink as independent sources.
If we remove all additional transformations and only keep the balance one, we do get the same source for credits and debits:
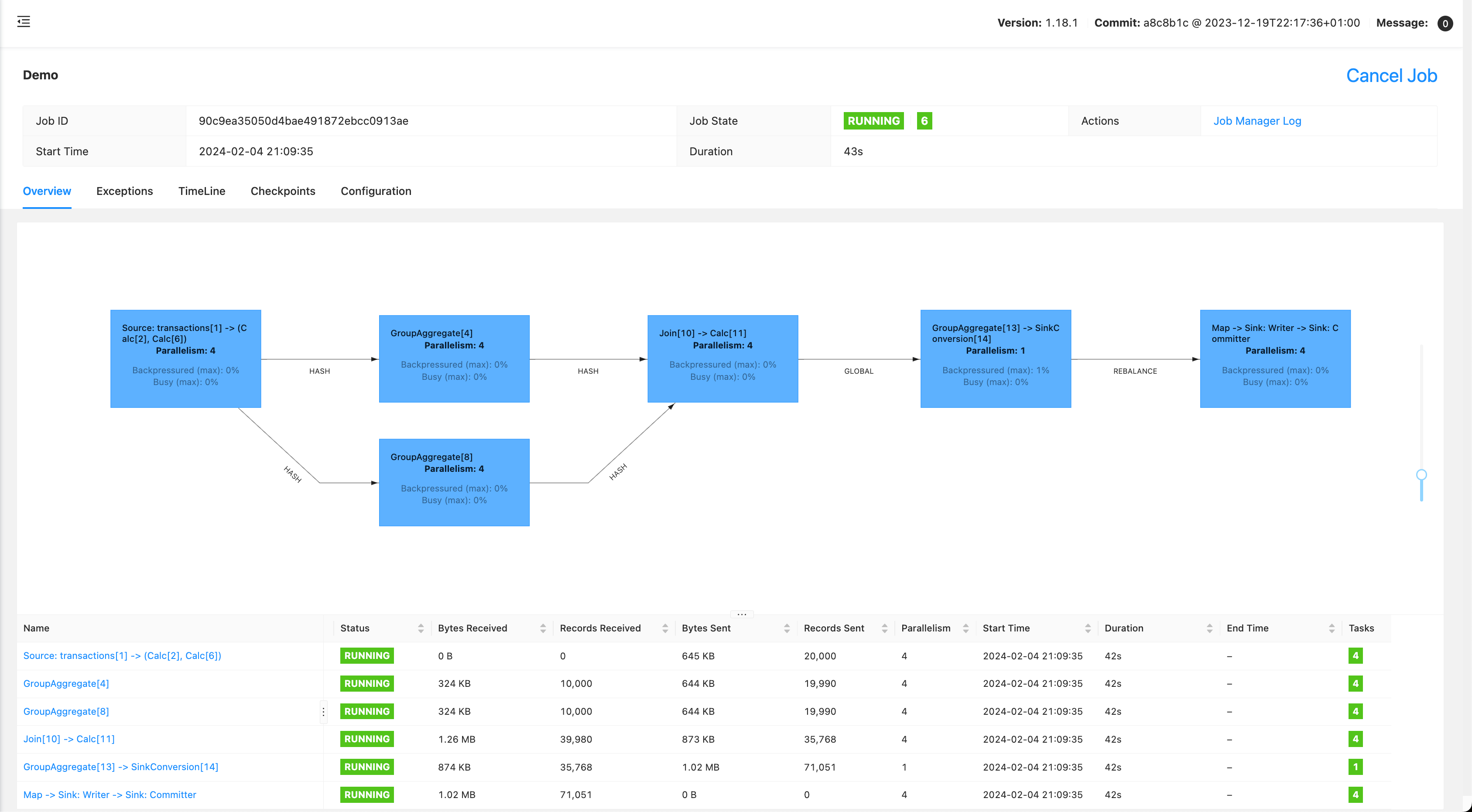
But this example still fails. Flink doesn’t have a way to synchronize data end-to-end as Timely Dataflow does. Flink has a few similar concepts:
Watermarks allow you to compute more accurate results when dealing with temporal computations. However, they’re not mandatory. Some computations are non-temporal by design, and using watermarks in their current form would be a big stretch.
Checkpoint barriers are another similar concept. Flink uses checkpointing for exactly-once delivery, so, in theory, this concept could be used for aligning data streams (checkpoint barriers are injected at the source and traverse the whole topology). But even enabling exactly-once delivery for the Kafka sink (which uses checkpointing internally) didn’t improve consistency.
And even if you can rely on something for the perfect data synchronization, Flink still won’t be internally consistent. Many operations like joins end up emitting multiple output records for one input. For example, retractions can come as UPDATE_BEFORE / UPDATE_AFTER pairs. From Jamie’s post:
As a side point, it's noticeable in flink that many joins and aggregates often produce 2 output events for every input event. If we chain many of these operators together in a complex computation we might start thrashing on exponentially increasing numbers of updates. In deep graphs it may actually be faster overall to wait at each operator long enough to merge redundant updates.
The situation is slightly better if it’s possible to use datastreams with primary keys defined. In this case, the UPDATE_BEFOREs can be effectively discarded, but they are still emitted by Flink (I think?).
This is why compacting a changelog of updates is so important in Differential Dataflow. Without it, internal consistency would be violated.
And here’s a curious discovery I made: I was only able to ensure eventual consistency (getting “0 balance” as a final write) with a parallelism of 1. When using parallelism > 1, sometimes “0 balance” came last, but not always. Flink has some deep issues related to changelog shuffling: FLINK-20374 and similar ones led to the introduction of SinkUpsertMaterializer (in my opinion, one of the worst band-aids I’ve seen). But it wasn’t added to the topology in the example, even after I tried forcing it.
Practical Solutions
I believe that leveraging upserts can be a good enough solution in situations where internal consistency is not available. See my previous post on this topic:
Also, in the case of Flink, I feel like it should be possible to tackle the changelog compaction issue by implementing a set of low-level DataStream operators. They may end up buffering and storing more state, but that’s the price to pay.
Adoption
It’s clear that guaranteeing internal consistency feels important. But in practice, very few systems do. And most of those systems rely on Timely and/or Differential Dataflow.
Materialize is a pioneer in this space. Frank McSherry, Materialize co-founder and chief scientist, co-authored the original papers and Rust implementation. Materialize’s blog is a great resource to learn about practical applications of Timely and Differential Dataflow.
Pathway is another company that built a product on top of Timely and Differential Dataflow. It chose to target Python as a primary language. The company makes some pretty strong claims (“fastest Rust runtime on the market”), and it’s worth checking out.
Bytewax is a similar product that targets Python, but they chose not to depend on Differential Dataflow, they only use Timely. It’s a great product that I highly recommend.
I couldn’t find any other production-ready products or tools that use Timely or Differential Dataflow. Some honourable mentions:
Differential Datalog (DDlog) - research project from VMware.
Dida (archived) - differential dataflow implementation in Zig (also by Jamie Brandon).
materialite (WIP) - differential dataflow implementation in Typescript.
GraphScope - graph processing platform that uses Timely Dataflow. This could probably be categorized under production-ready, but I don’t know much about its users.
I assumed that Arroyo and RisingWave used Timely and/or Differential Dataflow, but that’s not the case. However, it looks like RisingWave uses a similar approach to guarantee internal consistency.
Summary
I still have some unanswered questions when it comes to internal consistency. This is a fascinating topic, and I hope to learn more. But here’s my understanding right now:
Internal consistency means that every output is correct for some subset of inputs. In practice, that can mean delayed (or even dropped) data.
Timely and Differential Dataflow implement it by buffering and synchronizing intermediate results (this is mostly on Timely) as well as compacting changelog streams (this is mostly on Differential).
Flink has problems with both: it doesn’t have a robust end-to-end mechanism for synchronization (even though watermarks and checkpoint barriers look promising), and it’s too “noisy” when it comes to emitting changelog data. I feel like both might be addressed with low-level DataStream API operators.